и все-таки линейная... (ИМХО)

Александр, я не считаю, что модель эксплуатирует параболический вид функции. В модели, на мой взгляд, есть попытка "поймать" линейный тренд с коэффициентом ("весом") w
2
Формула для «следующего приближения»
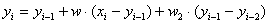
может быть записана таким образом:
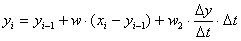
В нашем случае
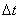
- время между барами, в «дискретной» модели
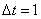
В таком виде видно, что модель использует численную линеаризацию по времени (не только по ошибке предыдущего приближения), «тренд» в модели оценивается как просто разность двух предыдущих известных значений сглаженной функции, взятой с каким-то весом.
Опять же – для построения точки используется информация о двух предыдущих точках, а по двум точкам только прямая строится.
Я думал, что модель МЕМА является аналогом Брауновской, только «в профиль». Даже хотел попытаться свести их аналитически друг к другу. Однако страшно хочется спать, а в таком состоянии можно делать только тупые вещи «ручками».
И, по всей видимости, МЕМА и Браун все-таки не одно и то же.
Я попробовал сравнить в экселе три модельки – ЕМА, МЕМА и Брауна с точки зрения ошибки аппроксимации на линейном (x = i) и параболическом (x = i + i
2) трендах исходной функции.
Параметры для ЕМА и МЕМА брал w = w2 = 0.1, для Брауна
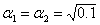
(в терминах книжки Лукашина 2003 года, там, если формулу развернуть, и если я не ошибся, получается коэффициент при разнице с предыдущей оценкой (аналог w) w =
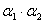
)
Посчитав этот коэффициент «ведущим», я так и выбрал. Вообще-то надо аккуратно исследовать, при каких параметрах модели будут «сравнимыми».
Все модели аппроксимировали линейный входной сигнал с ошибкой, стремящейся к константе, параболический – с линейно возрастающей ошибкой (кстати, это еще раз говорит о том, что «параболу» ни одно из приближений не эксплуатирует).
Картинки смотрятся вот так:
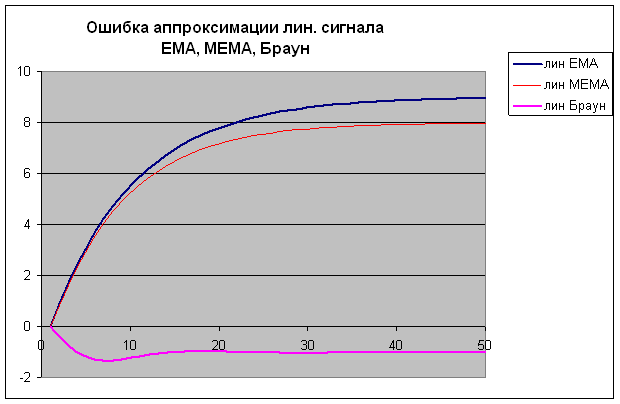
Здесь видно, что МЕМА лучше ЕМА, но, вообще говоря, не принципиально.
А Браун еще лучше (готов допустить, что коэффициенты взял не корректно – к аналитической работе я сейчас совсем не готов)
Нетрудно показать, кстати, что при w + w
2 = 1 МЕМА точно «попадает» в линейный сигнал (ошибка = 0).
Картинки по реальным рядам цен (просто кусок часовых данных логарифмов цен Лукойла):
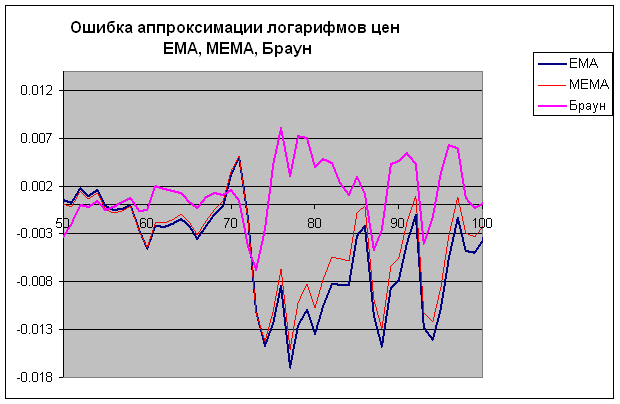
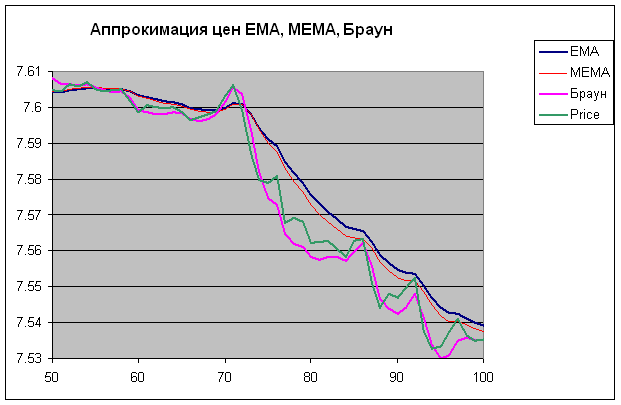
Опять же видно, что Браун получше аппроксимирует.
Повторюсь, с параметрами сглаживания я вполне мог накосячить, поэтому сравнение может быть некорректным.
В общем, резюмируя – все-таки считаю, что МЕМА эксплуатирует часть линейного, а не параболического тренда. Поправьте меня, если я где глубоко ошибся.
Интересно было бы (это такая просьба к Станиславу… ) посмотреть на сравнение моделей по МЕМА и Брауну на его большом фактическом материале.